用Python爬取中国医生电影评论生成词云并实现数据可视化(内附源码)
今日目标:爬取豆瓣电影中国医生评论实现数据可视化
前言
前段时间,主旋律电影《中国医生》上线,大家有没有去看呢?反正我去看了,有点感人(其实哭得稀里哗啦) 。看完后,内心感概万分,回到家缓了好久 。看了电影的海报画面,想着可以爬一爬大家对电影的评论,正好给大家写文了 。于是,利用下班时间给大家做了这个爬虫项目 。废话不多了,直接开整 。

文章插图
工具使用
开发环境
系统:Windows10 64位
Python版本:Python3.7
IDE:Pycharm
第三方库:selenium lxml re wordcloud PIL numpy jieba matplotlib
代码演示
饼图
文章插图
饼图
词云生成
文章插图
词云生成
柱状图生成
文章插图
柱状图生成
项目思路分析
1 获取网址规律

文章插图
可以看到 start 和 status是变化的关键
在这个页面可以通过xpath获取地址网页 评论详情 和评分
地址网页:

文章插图
评论详情:

文章插图
评分 :

文章插图
2 打开地址网页,获取地址信息
文章插图
有些没有地址信息 所有需要获取全部 后期通过数据处理获取有地址信息的
3 把获取的数据进行解析 分别存放三个文件
文章插图
4 通过读取相应的文件生成相应的图表
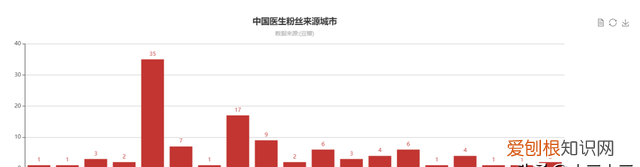
文章插图
项目难点分析
1 滑块验证
这个参考代码里面的滑块验证的方法
通过像素对比找到缺口
移动一段距离 之后速度变化慢慢往前面走 到达缺口就能够验证成功
2 切换iframe
# 切换iframedriver.switch_to.frame(1)需要切换iframe才能找到滑块和输入账号 密码 的元素位置3 显示等待
wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="profile"]/div/div[2]')))等待元素出现才进行下一步的处理4 数据处理
出现不合法的数据 比如 该用户已经主动注销帐号
判断源代码中是否存在 如果存在就跳过 防止等待时间过长 退出程序
if driver.page_source.__contains__("`该用户已经主动注销帐号`"):continue5 抓取思维采取先抓大再抓小
这样可以确定几个元素是相对应的
循环的时候会再次使用xpath 此时的xpath写法
需要加一个 .
item = {"href": email_detail.xpath('./div/a/@href'),"detail": email_detail.xpath("./div[2]/p/span//text()"),"rate": email_detail.xpath("./div[2]/h3/span[2]/span[2]/@class")}6 json模块默认编码默认:ascii码 为了中文的正确显示 需要传递参数ensure_ascii
f.write(json.dumps(email, ensure_ascii=False) + ",\n")7 词云图的生成
推荐阅读


- 土蛙和青蛙的区别,石蚌和青蛙有什么区别
- 和平县美食,广东河源有那些地方好玩的
- Excel表格中的宏怎么用,excel中函数的使用方法是什么
- 在cdr中怎样做投影,cdr中透明度怎样调节
- 如何使用word和excel,Word该咋插入Excel表格
- PS应该怎么才可以画五角星,用PS怎么将五边形变成五角星
- 如何保存ppt演示文稿,PPT做完以后怎么保存
- 一个字的网名
- 如何制作镂空的形状效果,如何用PPT制作透明镂空图形