文章插图
按照图片格式只需要添加一个参数即可mask
# graph 图片对象word_cloud = WordCloud(font_path="simsun.ttc",background_color="white",mask=graph, # 指定词云的形状)8 柱状图和饼图
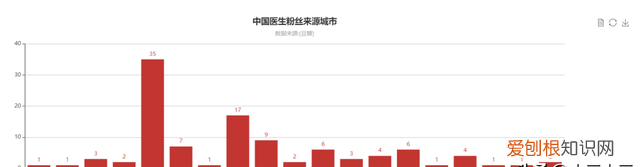
文章插图
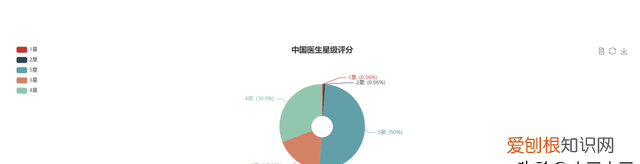
文章插图
难点在于json文件读取
循环获取的data 然后通过列表构建echarts需要的数据格式
$.getJSON("json_file/rate.json", function(data) {var x_data = http://www.baifabohui.com/smjk/[];for (var i = 0; i < data.length; i++) {console.log(data[i]);for(var key in data[i]){ // 输出字典元素,如果字典的key是数字,输出时会自动按序输出hello = {value: data[i][key], name: key+"星"}x_data[i] = hello;}};源码展示词云图
# 词云生成import jiebaimport numpy as npfrom wordcloud import WordCloudimport matplotlib.pyplot as pltfrom PIL import Imagetext = open("json_file/detail.text",encoding='utf8').read()text = text.replace('\n',"").replace("\u3000","")text_cut = jieba.lcut(text)text_cut = ' '.join(text_cut)# 主要区别background = Image.open("image/mmexport1626868510673.jpg")graph = np.array(background)word_cloud = WordCloud(font_path="simsun.ttc", background_color="white", mask=graph, # 指定词云的形状 )word_cloud.generate(text_cut)plt.subplots(figsize=(12,8))plt.imshow(word_cloud)plt.axis("off")plt.show()滑块验证def slide(driver): """滑动验证码""" # 切换iframe driver.switch_to.frame(1) # 找到滑块 block = driver.find_element_by_xpath('//*[@id="tcaptcha_drag_button"]') # 找到刷新 reload = driver.find_element_by_xpath('//*[@id="reload"]') while True: # 摁下滑块 ActionChains(driver).click_and_hold(block).perform() # 移动 ActionChains(driver).move_by_offset(180, 0).perform() # 获取位移 tracks = get_tracks(30) # 循环 for track in tracks: # 移动 ActionChains(driver).move_by_offset(track, 0).perform() # 释放 ActionChains(driver).release().perform() # 停一下 time.sleep(2) # 判断 if driver.title == "登录豆瓣": print("失败...再来一次...") # 单击刷新按钮刷新 reload.click() # 停一下 time.sleep(2) else: break打开文件获取清洗数据def get_file(): # 打开文件获取清洗数据 f = open('data.json', 'r', encoding="utf-8") hello = f.read() # 地址列表 评分列表 评论内容列表 address_ = [] rate_ = [] detail_ = [] # 按换行符进行 for i in hello.split("\n"): try: # 转换为字典 data = http://www.baifabohui.com/smjk/eval(i[:len(i) - 1]) # 获取评论详细内容 detail = data.get("detail")[0] # 获取评分 rate = re.findall("(/d{1})/d", data.get("rate")[0])[0] # 获取地址 address = ".".join(re.findall("常居: ([/u4e00-/u9fa5]{2})", "".join(data.get("address")))) # 地址存在则添加到地址列表中 if address: address_.append(address) # 把评分添加到评分列表中 rate_.append(rate) # 把评论添加到评论列表中 detail_.append(detail) except: continue获取评分和唯一地址# 获取评分和地址的唯一 rate_set = set(rate_) address_set = set(address_) # 写入 评分json with open("json_file/rate.json", 'w', encoding="utf-8") as file: rate_json_list = [] for r in rate_set: # 获取评分频次并且构造字典 rate_json = {r: rate_.count(r)} rate_json_list.append(rate_json) file.write(json.dumps(rate_json_list, ensure_ascii=False))写入地址json文件# 写入地址json文件 with open("json_file/address.json", 'w', encoding="utf-8") as file: address_json_list = [] for a in address_set: # 获取地址频次并且构造字典 address_json = {a: address_.count(a)} address_json_list.append(address_json) file.write(json.dumps(address_json_list, ensure_ascii=False))
推荐阅读
-

-
-
-
-

-
-
-
-
-
- 土蛙和青蛙的区别,石蚌和青蛙有什么区别
- 和平县美食,广东河源有那些地方好玩的
- Excel表格中的宏怎么用,excel中函数的使用方法是什么
- 在cdr中怎样做投影,cdr中透明度怎样调节
- 如何使用word和excel,Word该咋插入Excel表格
- PS应该怎么才可以画五角星,用PS怎么将五边形变成五角星
- 如何保存ppt演示文稿,PPT做完以后怎么保存
- 一个字的网名
- 如何制作镂空的形状效果,如何用PPT制作透明镂空图形