概要: 怎样让电脑辨识一只猫?责任编辑从人重新认识猫的基本上方式侧发力,传授怎样体能训练电脑赢得数学模型的主要就关键步骤,并展开单纯的课堂教学,撷取了电脑自学的两个基本上原理——梯度下降实现非线性回归 。(variations福利:阿里云 AI 视觉体能夏令营,AI 资源、课程等你来) 作者:溪夏

文章插图
一 是甚么是电脑自学,为甚么他们要电脑自学甚么是电脑自学先看两个例子:
他们是怎样逻辑思维“猫”那个鸟类的?
想象一下两个从来没有见过猫的人(比如说两个小婴孩),他的词汇里面甚至没有猫那个词 。有一天他看到了两个毛茸茸的鸟类:

文章插图
这时他不晓得这是甚么东西,你说他这是 ”猫“ 。这时可能将小婴孩读懂了,那个是猫 。
又过了几天他又看到了这样两个鸟类:

文章插图
你又说他这也是猫 。他读懂了这也是猫 。
后来又过了几天,他又看到了两个鸟类:

文章插图
这时他直接说你他看到了一只“猫” 。
以上是他们重新认识世界的基本上方式,模式辨识:人们透过大量的经验,获得推论,进而推论它是猫 。
在那个过程中他们透过接触样本(各种猫)自学到了猫的特点(人们透过阅读展开自学,观察它会叫、四只嘴巴、三条腿、两条四肢、有胡子,获得推论),进而晓得甚么是猫 。
他们怎样晓得 npm 包推论两个 npm 包是试验 npm 包呢?
我贴一段爸爸妈妈的代码:
SELECT * FROMtianma.module_xxWHEREpt = TO_CHAR(DATEADD(GETDATE(), - 1, ‘dd’), ‘yyyymmdd’)AND name NOT LIKE ‘%test%’AND name NOT LIKE ‘%demo%’AND name NOT LIKE ‘%试验%’AND keywords NOT LIKE ‘%test%’AND keywords NOT LIKE ‘%试验%’AND keywords NOT LIKE ‘%demo%’很明显他们推论的方式是那个组件的名称和URL中与否包含:test、demo、试验这三个字符 。如果有那么他们就认为他是试验组件 。他们把规则说了统计资料库,然后统计资料库就帮他们筛选了非试验组件 。
辨识是不是猫或是辨识两个组件是不是试验组件本质上是一样的,都是在找特点:
猫的特点:会叫、四只嘴巴、三条腿、两条四肢、有胡子试验组件的特点:test、demo、试验更进一步将特点系统化表述:
猫的特点 叫:true、嘴巴:2、腿:4、四肢:1、胡子:10试验组件的特点:test:count>0、demo:count >0、试验:count > 0有了这些特点无论是人还是电脑都能正确的辨识猫或是试验组件了 。
单纯的认知电脑自学是透过特点和特点的权重来实现统计数据的展开分类 。(此处为了便于认知,更准确说法请参考:AiLearning/1.电脑自学此基础.md at master · apachecn/AiLearning · GitHub)
为甚么要用电脑辨识呢?原因是当某种展开分类各项任务的特点数目巨大之后他们就很难用 if else 的方式去做单纯的展开分类了 。比如说他们常用的货品所推荐演算法,要确认某个货品与否适合所推荐给某人可能将的特点数目会达到上千上百个 。
二 怎样体能训练电脑,并赢得数学模型?预备统计数据统计数据的预备在整个电脑自学的各项任务中时间占比可能将超过 75%,是最重要的一小部分,也是最困难的一小部分 。主要就是:
采集基本上的统计数据清理异常值挑选可能将的特点:特点工程统计数据陈建力预备演算法让你的统计数据展开插值的两个表达式:y=f(x)
比如说非线性表达式也是一元一次表达式:y=ax+b
评估结果演算法怎样确认找到的 a、b 值与否合适,那就需要两个评估结果表达式 。
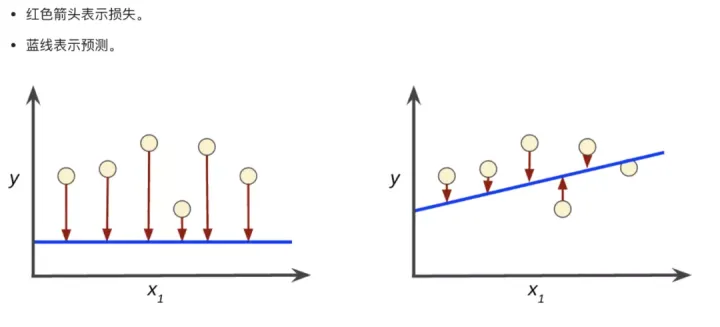
评估结果表达式描述体能训练获得的参数和实际的值之前的差距(经济损失值) 。比如说右图:
文章插图
右边的蓝色线条更加贴近真实世界的统计数据点 。
【零基础电脑入门免费课,零基础入门机器学习:如何识别一只猫?】最常用的经济损失评估结果表达式是TNUMBERHOYA误差表达式了 。透过计算预测的值和真实世界值的差的算式来推论预测值的优劣程度 。
如上图:样本黄色的小圆圈坐标为:
[
[x1, y1],[x2, y2],[x3, y3],[x4, y4],[x5, y5],[x6, y6]],
蓝色的线预测的坐标为:
[
[x1, y’1],[x2, y‘2],[x3, y’3],[x4, y‘4],[x5, y’5],[x6, y‘6]],
那么经济损失值为:
const cost = ((y’1-y1)^2 + (y’2-y2)^2 + (y’3-y3)^2 + (y’4-y4)^2 + (y’5-y5)^2 + (y’6-y6)^2 ) / 6体能训练演算法怎样找到合适的 a、b 值:抛物线的最低端
以上述的非线性表达式为例,体能训练演算法实际上是在寻找合适的 a,b 值 。如果他们在茫茫的数字海洋中随机寻找 a,b 的值那应该是永远找不到的了 。这时他们就需要用到梯度下降演算法来寻找 a,b 值了 。
再明确一下目标,将上述的经济损失值计算公式替换为:y=ax+b
// 表达式 2const cost = (((a*x1+b)-y1)^2 + ((a*x2+b)-y2)^2 + ((a*x3+b)-y3)^2 + ((a*x4+b)-y4)^2 + ((a*x5+b)-y5)^2 + ((a*x6+b)-y6)^2 )/ 6目标是找到一组 a、b 的值使得 cost 最小 。有了那个目标就好办多了 。
不晓得你还记不记得初中的抛物线表达式,也是一元二次方程:y = ax^2+bx+c
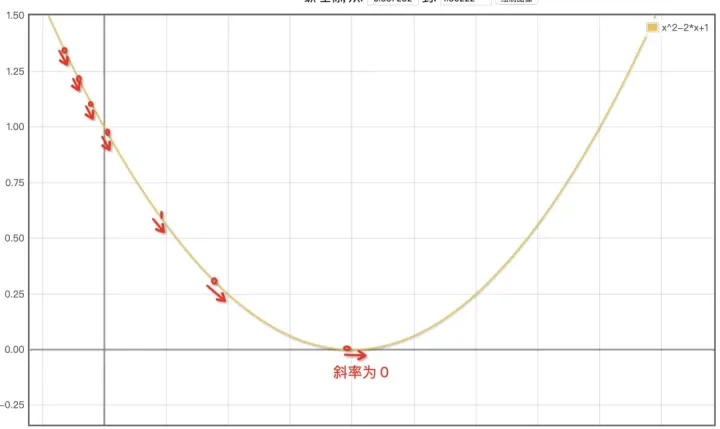
而他们上述的 cost 表达式虽然看起来很长,但是正好也是两个二次表达式 。它的图大概是这样的:
文章插图
只要他们找到最低点的 a,b 值就完成他们的目标了 。
怎么晓得到达抛物线的低端:抛物线的低端斜率为 0
假设他们随机初始化两个 a 值为 1, 这时他们的点就在抛物线的左上方位置,距离最低点(cost 最小)的位置还距离很远呢 。
看图可知他们只要增加 a 的值就可以靠近最低点了 。那看图电脑可不会,这时他们要祭出本篇文章中最复杂的数学知识了:导数 。在那个点上的切线斜率值即为那个抛物线的导数,如上图最低点(斜率为 0 处) 。
透过那个导数可以计算出那个位置的切线(红色的斜线)斜率 。如果那个斜线的斜率为负数就意味着 a 太小了,需要增加才能更靠近底部 。反之如果斜率为正意味着过了最低点了,需要减少才能更靠近底部 。
怎样求 cost 表达式的导数呢?
不展开了,直接看代码吧 。URL:偏导数、复合求导
// 表达式 3// a参数的偏导数const costDaoA = (((a*x1+b)-y1)*2*x1 + ((a*x2+b)-y2)*2*x1 + ((a*x3+b)-y3)*2*x1 + ((a*x4+b)-y4)*2*x1 + ((a*x5+b)-y5)*2*x1 + ((a*x6+b)-y6)*2*x1 )/ 6// b参数的偏导数const costDaoB = (((a*x1+b)-y1)*2 + ((a*x2+b)-y2)*2 + ((a*x3+b)-y3)*2 + ((a*x4+b)-y4)*2 + ((a*x5+b)-y5)*2 + ((a*x6+b)-y6)*2 )/ 6也是只要将 a,b 值带入 costDaoA 表达式就可以获得两个斜率,那个斜率指导参数 a 该怎样调整以便更靠近底部 。
同理 costDaoB 指导参数 b 改怎样靠近底部 。
循环 500 次吧
就这样循环 500 次,基本上上就能非常靠近底部了,进而赢得合适的 a,b 值 。
赢得数学模型当你赢得了 a,b 值之后,那么他们就赢得了 y=ax+b 这样两个数学模型,那个数学模型就可以帮助他们做预测了 。
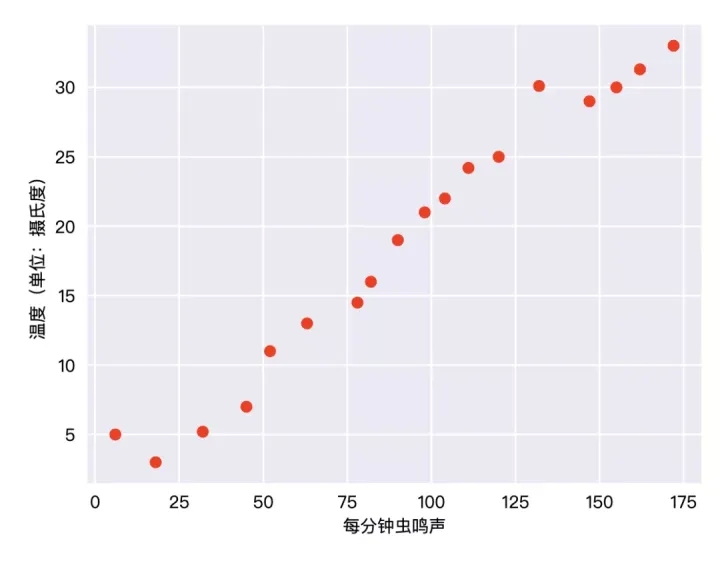
三 课堂教学一下先从单纯的开始:非线性回归甚么是非线性回归人们早就知晓 ,相比凉爽的天气,蟋蟀在较为炎热的天气里鸣叫更为频繁 。他们记录了气温和每分钟叫声的两个表格,并且在 Excel 中绘制了右图(案例来自 google tf 的官方教程):
文章插图
是不是很清晰,这些小红点几乎排在了两条直线上:

文章插图
那么他们就认为这些统计数据的分布是非线性的,绘制的这条直线的过程是非线性回归 。有了这条曲线他们就能准确的预测任何问题下鸣叫的次数了 。
用浏览器做两个非线性回归演示地址:试验梯度下降
https://jshare.com.cn/feeqi/CtGy0a/share?spm=ata.13261165.0.0.6d8c3ebfIOhvAq

文章插图
为了可视化采用了 highcharts 做统计数据可视化,同时为了省下 75% 的时间直接用了 highcharts 的默认统计数据点:
https://www.highcharts.com.cn/demo/highcharts/scatter当体能训练完成后绘制了两条蓝色的线叠加在了图上,同时增加了每次体能训练的 a,b 值的经济损失率曲线 。
代码介绍/*** 代价表达式 TNUMBERHOYA差计算*/function cost(a, b) {let sum = data.reduce((pre, current) = >{return pre + ((a + current[0] * b) - current[1]) * ((a + current[0] * b) - current[1]);},0);return sum / 2 / data.length;}/*** 计算梯度* @param a* @param b*/function gradientA(a, b) {let sum = data.reduce((pre, current) = >{return pre + ((a + current[0] * b) - current[1]) * (a + current[0] * b);},0);return sum / data.length;}function gradientB(a, b) {let sum = data.reduce((pre, current) = >{return pre + ((a + current[0] * b) - current[1]);},0);return sum / data.length;}// 体能训练次数let batch = 200;// 每次的靠近底部的速度,也是自学速率 。过高会导致在底部弹跳迟迟不能到到底部,过低会导致自学效率降低 。let alpha = 0.001;let args = [0, 0]; // 初始化 a b 值function step() {let costNumber = (cost(args[0], args[1]));console.log(‘cost’, costNumber);chartLoss.series[0].addPoint(costNumber, true, false, false);args[0] -= alpha * gradientA(args[0], args[1]);args[1] -= alpha * gradientB(args[0], args[1]);if ((—batch > 0)) {window.requestAnimationFrame(() = >{step()});} else {drawLine(args[0], args[1]);}}step();四 接下来要做的当特点更多的时候,他们需要更多的计算、更长时间的体能训练来赢得体能训练数学模型 。
上述描述都比较单纯,但是相信电脑自学对你已经不再神秘,那么可以参考更专业的进阶文章 。
参考
[1] GitHub - apachecn/AiLearning: AiLearning: 电脑自学 - MachineLearning - ML、深度自学 - DeepLearning - DL、自然语言处理 NLP
[2] https://developers.google.com/machine-learning/crash-course/descending-into-ml/video-lecture?hl=zh-cn[3] 从 0 开始电脑自学 - 手把手用 Python 实现梯度下降法!- 掘金 福利来了 | 阿里云 AI 视觉体能夏令营
加入阿里云高校计划 AI 视觉体能夏令营,与达摩院视觉导师亲密接触 。五天时间玩转身份证辨识应用、电子相册应用、图像辨识项目、车辆辨识项目 。
点击“阅读原文”马上参与!
推荐阅读


- 挖地菜作文350字
- 学习方法作文
- 给表妹的一封信作文600字
- 鸿运当头怎么养花才会红,鸿运当头怎么养护才能花叶更绿,花色更红,人见人爱
- 《小猫出生在秘密山洞》-读后感作文500字
- 网球握拍位置
- 猫怎么看品相好不好,怎么看猫的品相?看完后买猫再也不被忽悠了!
- 鸿运当头的花平时该怎么养,鸿运当头这样种植花多还很鲜艳
- 纯的葡萄酒多少度