(2) 缺点
- 逻辑非常复杂
- 可能存在回溯情况,可能需要记忆已匹配的前N个字符,效率低
- 大量IF判断,可维护性差,扩展性差
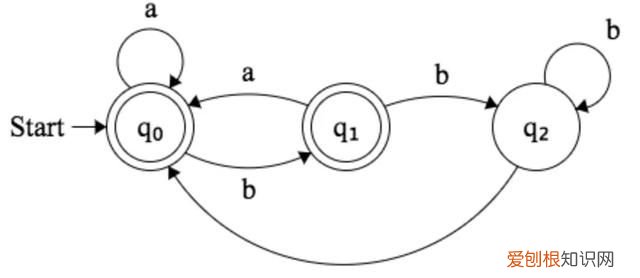
DFA即deterministic finite automaton有限状态自动机,其特点是可以实现状态的自动转移,可以用于解决字符匹配问题
(1) 核心构成
DFA的核心构成要素是状态和状态的转移
- 定义自动机所具备的N种状态,并定义初始状态
- 定义上一个状态转移至下一个状态的条件
文章插图
(2) 应用实践
如何用DFA实现词法分析器呢,步骤如下
- 先定义不同的状态 :如操作符状态、数字状态、符号状态等
- 再定义状态转移条件 :如当前状态是初始状态,遇到数字则转移至数字状态,遇到符号则转移至符号状态
- 如果字符读取完成,则整个转移过程结束
let state = 0; // 当前状态, 也是初始状态while ((ch = nextChar()) !== false) { let match = false; // 获取下一个状态, 如果下一个状态不是初始状态, 则说明匹配成功 let nextState = getNextState(ch, state); if (nextState) { match = true; } // 如果匹配成功, 则字符读取序列的下标+1,并转移至下一个状态 if (match) { incrSeq(); flowtoNextState(ch, nextState); } else { // 不匹配则生成token,并转移至初始状态,开始重新匹配 produceToken(); flowtoResetState(); }}复制代码(4) 优点- 逻辑清晰简单
- 可维护性高,可扩展能力高
- 时间复杂度为O(N),效率高
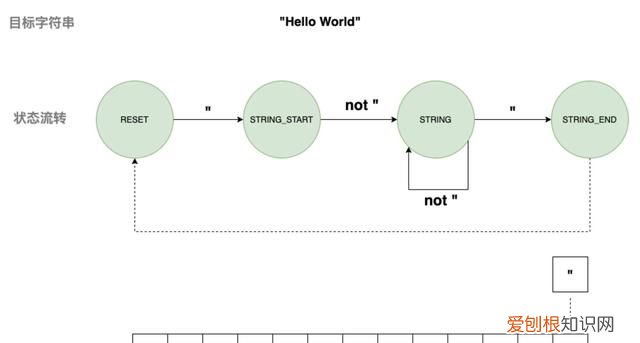
1) 匹配字符串
文章插图
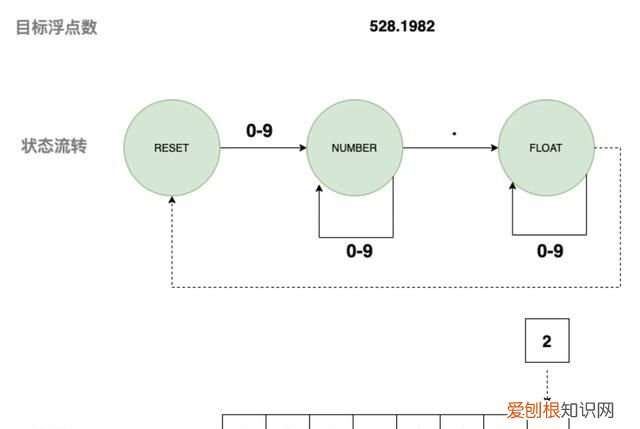
2) 匹配浮点数
文章插图
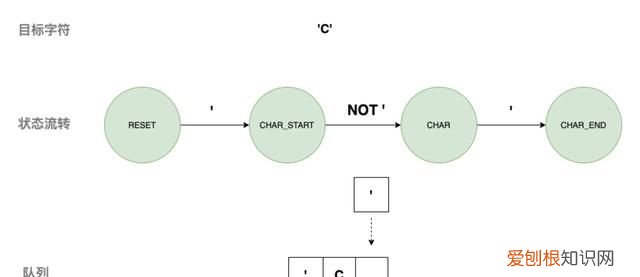
3) 匹配字符
文章插图
【编译程序中的词法分析器的输出是二元组】4) 匹配运算符
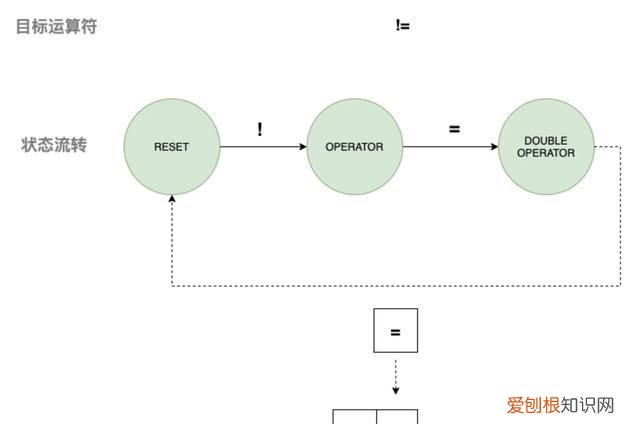
文章插图
五、词法分析器的实现
词法分析器的详细实现及源码讲解,参见 ***/WGrape/lexer 项目
六、结束语
本文已结束,感谢阅读,点击查看原文
推荐阅读


- 暴风魔镜app旧版本? 暴风影音飞屏版电脑端+魔镜端使用教程且魔镜APP怎么用
- 如何清理钉钉的空间,浙政钉清理缓存会删除记录吗
- 深入人心的励志语录句子,保证你看了还想看!
- 学前教育专业学什么,学前教育专业主要课程是什么
- 魔渊之刃困难5怎么打,宠物天才怎样,打败第十五层
- 豆瓣2022经典的软文推广素材励志,句句经典走心!
- 陆风x7电源故障怎么解决,陆风x7出现电源故障是什么原因
- 豆瓣2022排名榜的软文推广素材励志,句句深入人心!
- 语文朗读语调主要有哪几种